© 2023 yanghn. All rights reserved. Powered by Obsidian
9.3 深度循环神经网络
要点
- 一般多层神经网络里面,每一层的隐藏元大小是一致的
- 一般来说取两层,因为最后输出的时候还有一层 dense layer(CNN 的 FC 层也没有很多)
1. 基本思想
目前为止只基于单层网络,为了让状态更具有非线性关系,实际上可以将状态构造为多层神经网络
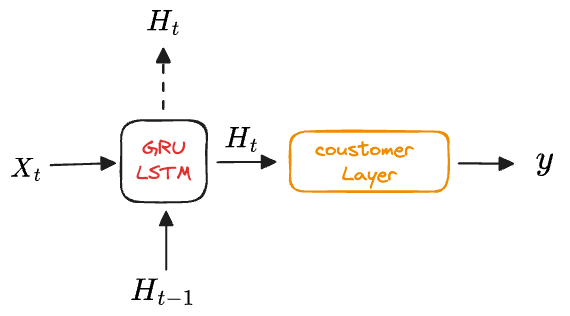
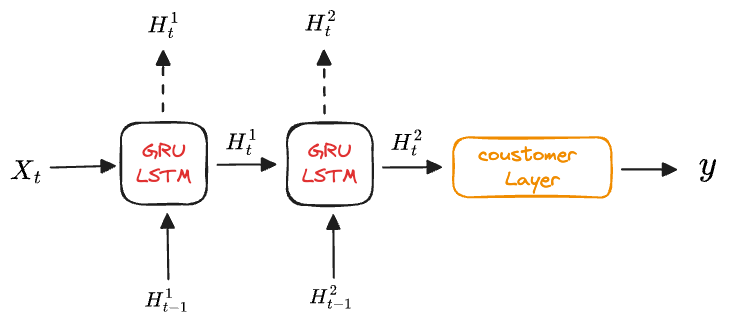
- 第一层等价于普通的 RNN,输入当前
和上一时间步的状态 得到 - 第二层输入上一层传过来的
和上一时间步的状态 得到
假设在时间步
其中, 权重
其中, 权重
2. 简洁实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
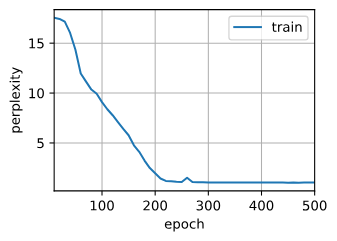
训练与预测
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr*1.0, num_epochs, device)
perplexity 1.0, 186005.7 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filb